环境准备 1 2 3 4 gym 0.26 .2 0.0 .8 2.1 .0 1.9 .0 +cu111
游戏搭建与测试 测试游戏使用的是 gym 库的CartPole-v1 游戏模型。
首先要对游戏环境进行初始化和启动:
1 2 3 4 'CartPole-v1' , render_mode='human' )
然后,是人类玩家通过键盘来玩游戏,测试和了解游戏的规则以及难度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def human_play (action_max ):1 )print ("游戏开始!" )0 False 0 ] 1 ] 2 ] 3 ] for step in range (1 , action_max + 1 ):0.2 )0 if not key[pygame.K_LEFT] and not key[pygame.K_RIGHT]:if key[pygame.K_LEFT]:0 elif key[pygame.K_RIGHT]:1 print (f"步骤={step} 行为={action} " f" 车速={car_speed:.2 f} 位置={car_position:.2 f} " f" 角度={pole_angle:.2 f} 尖端速度={pole_speed:.2 f} " )if terminated:True print ('Done!' )break if fail:print (f"游戏失败!你坚持了 {game_time:.2 f} 秒 {step} 步。" )else :print (f"游戏通关!你坚持了 {game_time:.2 f} 秒 {step} 步。" )
游戏结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 步骤=1 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 2 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 3 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 4 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 5 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 6 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 7 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 8 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 9 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 10 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 11 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 12 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 13 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 14 行为=1 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 15 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 16 行为=0 车速=0.03 位置=-0.04 角度=-0.01 尖端速度=-0.03 3.63 秒 16 步。
于是,定义一个简易的神经网络来玩游戏。
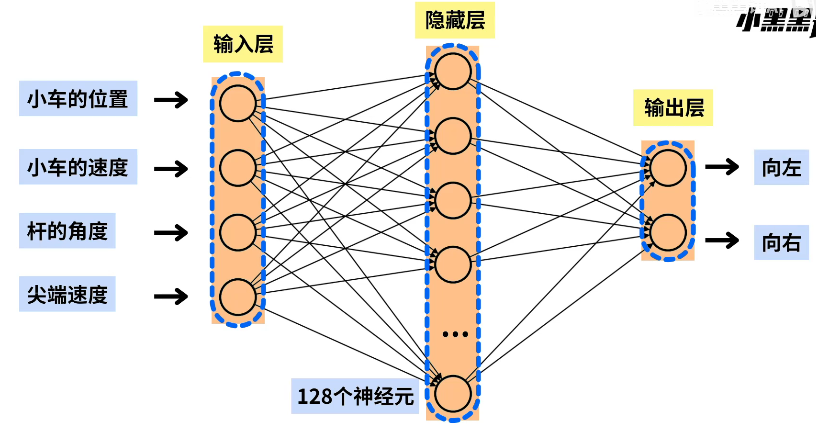
强化学习模型 神经网络
定义的神经网络如上图,输入小车的四个实时特征 ,输入一个 128 神经元的隐藏层神经网络,最后再输出为向左、向右的概率大小 ,让神经网络决定小车的向左/向右。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class CartPolePolicy (nn.Module):def __init__ (self ):super (CartPolePolicy, self ).__init__()self .fc1 = nn.Linear(in_features=4 , out_features=128 )self .fc2 = nn.Linear(in_features=128 , out_features=2 )self .drop = nn.Dropout(p=0.6 )def forward (self, x ):self .fc1(x)self .drop(x)self .fc2(x)return F.softmax(x, dim=1 )
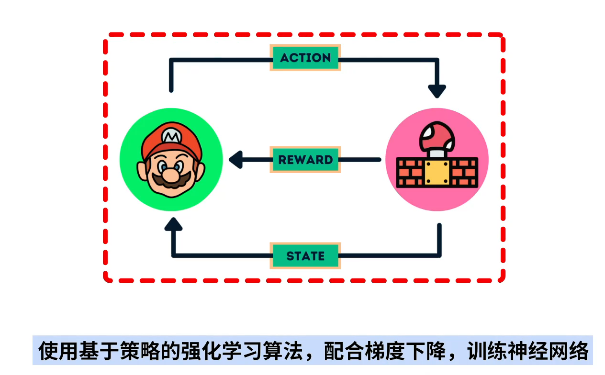
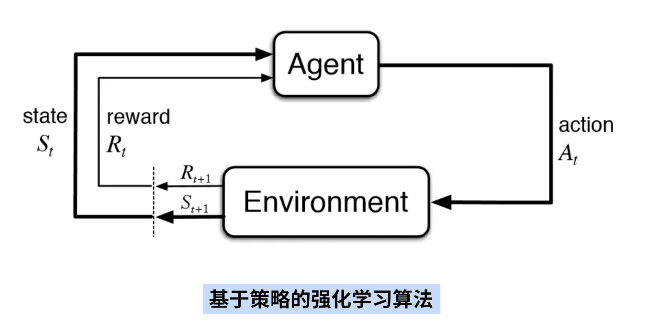
强化学习算法
基于策略的强化学习模型其算法而结构如下:
在此处,我们假设 Cartpole 游戏执行了 n 步:
神经网络的行动:$ a1,a2,…….an\in0、1 $
选择动作的概率:$ p1,p2,……pn
动作对应的奖励:$ r1,r2,……rn $
总奖励为:$ R=p1r1+p2 r2+……+pn*rn $
于是,我们神经网络的参数优化目标为:总奖励 R 最大 。
也就是说,增加神经网络输出高奖励动作的概率,减少输出低奖励动作的概率。
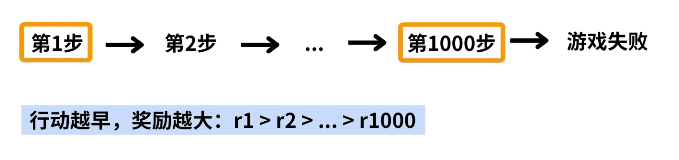
问题就在于:如何分配奖励?
奖励策略 对于 Cartpole 游戏而言:
如果游戏没有结束 ——>正奖励
如果游戏结束 ——>不再奖励
由于第 1 步做出了正确的决定,才有了第 2 步,所以应该给第一步更多的奖励。
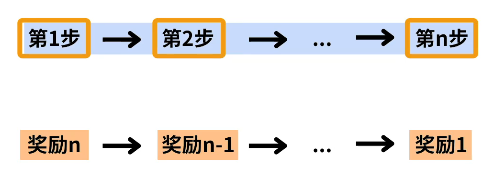
所设定奖励策略如下:
损失函数 定义损失函数为:$ loss=-\sum_{i=1}^{n} log(p_i)\cdot r_i $
第 i 步的行动为:$ p_i = \pi(a_i|s_i) $
第 i 步的奖励为:$ r_i=n-i+1 $
神经网络的训练目标即为:使 loss 函数最小的参数模型,即使总奖励 R 最大,
1 2 3 4 5 6 7 8 9 10 11 12 13 def compute_policy_loss (n, log_p ):list ()for i in range (n, 0 , -1 ):1.0 )0 for pi, ri in zip (log_p, r):return loss
进行训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def train ():543 )543 )0.01 )''' 一共训练最多1000回合 每回合罪多行动10000次 当某一回合的游戏步数超过5000,就认为训练完成 ''' 1000 10000 5000 for episode in range (1 , max_episode + 1 ):0 list ()for step in range (1 , max_actions + 1 ):float ().unsqueeze(0 )''' 这里不是直接使用概率较大的行动,而是通过概率分布生成action, 这样可以进一步探索低概率的行动。 ''' if done:break if step > max_steps:print (f"完成!上一轮训练为{episode} ,步数为{step} " )break if episode %10 == 0 :print (f'Episode{episode} Run steps{step} ' )f'catpole_policy.pth' )
AI 测试 接下来让训练生成的模型去玩游戏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 def ai_play (action_max ):1 )print ("游戏开始!" )0 False 0 ] 1 ] 2 ] 3 ] 'catpole_policy.pth' ))eval () for step in range (1 , action_max + 1 ):0.1 )'''小车控制的方式''' float ().unsqueeze(0 )1 ).item()print (f"步骤={step} 行为={action} " f" 车速={car_speed:.2 f} 位置={car_position:.2 f} " f" 角度={pole_angle:.2 f} 尖端速度={pole_speed:.2 f} " )if done:True print ('Done!' )break if fail:print (f"游戏失败!你坚持了 {game_time:.2 f} 秒 {step} 步。" )else :print (f"游戏通关!你坚持了 {game_time:.2 f} 秒 {step} 步。" )
测试结果:
1 2 3 4 5 6 7 步骤=995 行为=0 车速=0.02 位置=-0.03 角度=0.01 尖端速度=-0.03 996 行为=1 车速=0.02 位置=-0.03 角度=0.01 尖端速度=-0.03 997 行为=1 车速=0.02 位置=-0.03 角度=0.01 尖端速度=-0.03 998 行为=0 车速=0.02 位置=-0.03 角度=0.01 尖端速度=-0.03 999 行为=0 车速=0.02 位置=-0.03 角度=0.01 尖端速度=-0.03 1000 行为=1 车速=0.02 位置=-0.03 角度=0.01 尖端速度=-0.03 42.00 秒 1000 步。
截取部分结果,可见 AI 成功的完成了 1000 步,说明模型很成功。