Unet神经网络图像分割研究与应用
Unet神经网络图像分割研究与应用
一、概述
语义分割(Semantic Segmentation)是图像处理和机器视觉一个重要分支。与分类任务不同,语义分割需要判断图像每个像素点的类别,进行精确分割。语义分割目前在自动驾驶、自动抠图、医疗影像等领域有着比较广泛的应用。

上图是基本的语义分割任务。
Unet可以说是最常用、最简单的一种分割模型了,它简单、高效、易懂、容易构建、可以从小数据集中训练。Unet已经是非常老的分割模型了,是2015年《U-Net: Convolutional Networks for Biomedical Image Segmentation》提出的模型,附件中会给出文章文件。
在Unet之前,则是更老的FCN网络,FCN是Fully Convolutional Netowkrs的碎屑,不过这个基本上是一个框架,到现在的分割网络,谁敢说用不到卷积层呢。 不过FCN网络的准确度较低,不比Unet好用。
二、Unet网络结构与优势
1、Encoder Part

蓝/白色框表示 feature map;蓝色箭头表示 3x3 卷积,用于特征提取;
灰色箭头表示 skip-connection,用于特征融合;
红色箭头表示池化 pooling,用于降低维度;
绿色箭头表示上采样 upsample,用于恢复维度;
青色箭头表示 1x1 卷积,用于输出结果。
Encoder 由卷积操作和下采样操作组成,文中所用的卷积结构统一为 3x3 的卷积核,padding 为 0 ,striding 为 1。没有 padding 所以每次卷积之后 feature map 的 H 和 W 变小了,在 skip-connection 时要注意 feature map 的维度(其实也可以将 padding 设置为 1 避免维度不对应问题),pytorch 代码:
1 | |
上述的两次卷积之后是一个 stride 为 2 的 max pooling,输出大小变为 1/2 *(H, W):
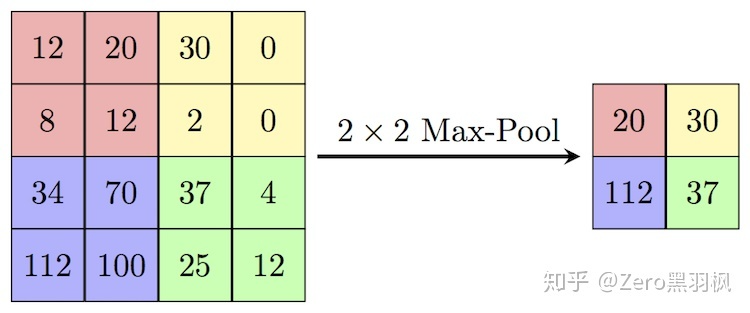
1 | |
2、Decoder Part
feature map 经过 Decoder 恢复原始分辨率,该过程除了卷积比较关键的步骤就是 upsampling 与 skip-connection。
Upsampling 上采样常用的方式有两种:1.FCN 中介绍的反卷积;2. 插值。在插值实现方式中,bilinear 双线性插值的综合表现较好也较为常见 。
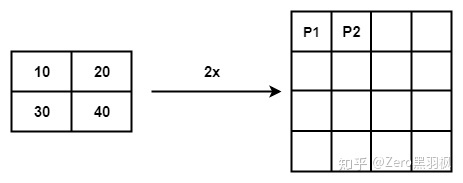
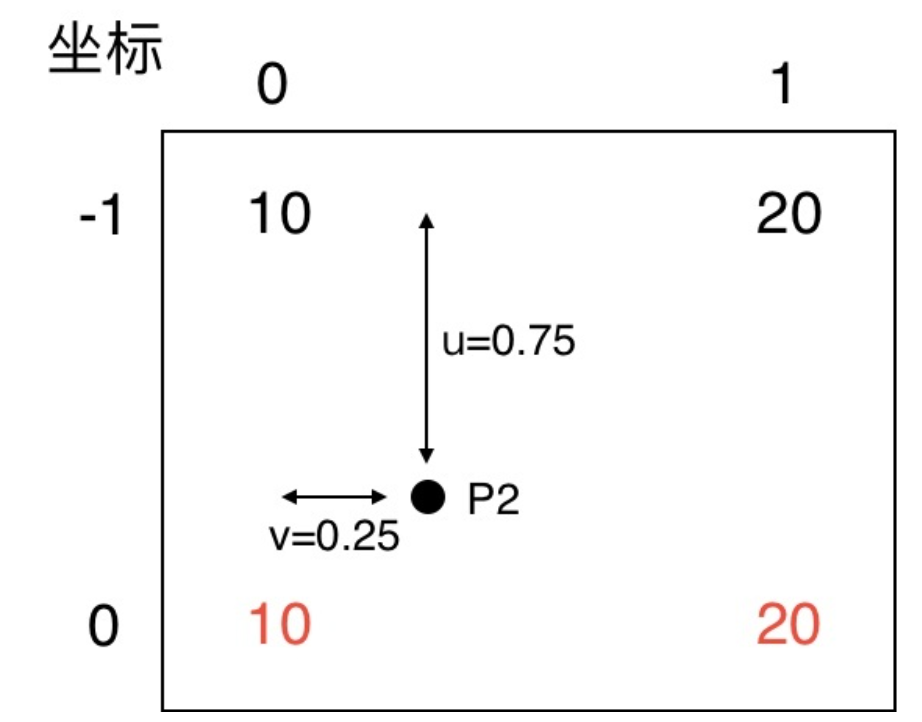
例子中是将一个 2x2 的矩阵通过插值的方式得到 4x4 的矩阵,那么将 2x2 的矩阵称为源矩阵,4x4 的矩阵称为目标矩阵。双线性插值中,目标点的值是由离他最近的 4 个点的值计算得到的,我们首先介绍如何找到目标点周围的 4 个点,以 P2 为例。
第一个公式,目标矩阵到源矩阵的坐标映射:
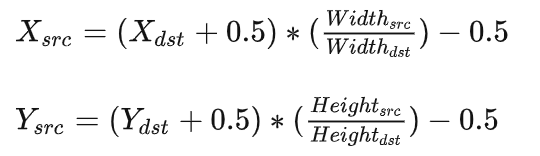
为了找到那 4 个点,首先要找到目标点在源矩阵中的相对位置,上面的公式就是用来算这个的。P2 在目标矩阵中的坐标是 (0, 1),对应到源矩阵中的坐标就是 (-0.25, 0.25)。坐标里面居然有小数跟负数,不急我们一个一个来处理。我们知道双线性插值是从坐标周围的 4 个点来计算该坐标的值,(-0.25, 0.25) 这个点周围的 4 个点是(-1, 0), (-1, 1), (0, 0), (0, 1)。为了找到负数坐标点,我们将源矩阵扩展为下面的形式,中间红色的部分为源矩阵。
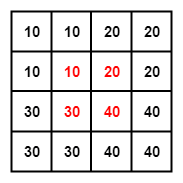
我们规定 f(i, j) 表示 (i, j)坐标点处的像素值,对于计算出来的对应的坐标,我们统一写成 (i+u, j+v) 的形式。那么这时 i=-1, u=0.75, j=0, v=0.25。把这 4 个点单独画出来,可以看到目标点 P2 对应到源矩阵中的相对位置。
第二个公式,也是最后一个。
$ f(i + u, j + v) = (1 - u) (1 - v) f(i, j) + (1 - u) v f(i, j + 1) + u (1 - v) f(i + 1, j) + u v f(i + 1, j + 1) $
目标点的像素值就是周围 4 个点像素值的加权和,明显可以看出离得近的权值比较大例如 (0, 0) 点的权值就是 0.750.75,离得远的如 (-1, 1) 权值就比较小,为 0.250.25,这也比较符合常理吧。把值带入计算就可以得到 P2 点的值了,结果是 12.5 与代码吻合上了,nice。
1 | |
CNN 网络要想获得好效果,skip-connection 基本必不可少。Unet 中这一关键步骤融合了底层信息的位置信息与深层特征的语义信息,
1 | |
这里需要注意的是,FCN 中深层信息与浅层信息融合是通过对应像素相加的方式,而 Unet 是通过拼接的方式。
那么这两者有什么区别呢,其实 在 ResNet 与 DenseNet 中也有一样的区别,Resnet 使用了对应值相加,DenseNet 使用了拼接。个人理解在相加的方式下,feature map 的维度没有变化,但每个维度都包含了更多特征,对于普通的分类任务这种不需要从 feature map 复原到原始分辨率的任务来说,这是一个高效的选择;而拼接则保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势。
3、上述模型结构在医疗影像中的优势
深度学习用于医学影像处理的一个挑战在于,提供的样本往往比较少,而 U-Net 则在这个限制下依然有很好的表现:
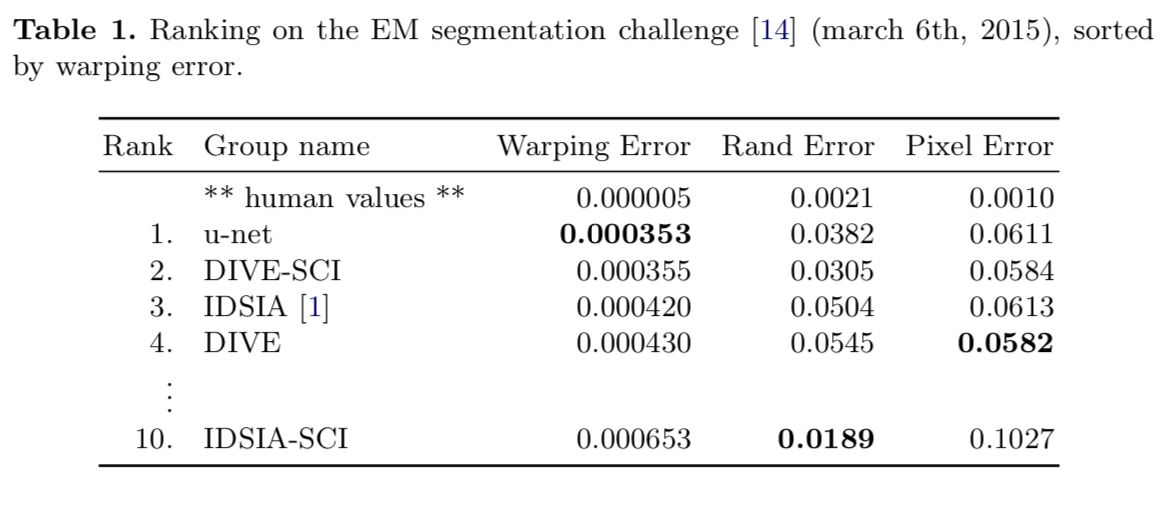
根据网友对Unet医疗领域应用的讨论,得到的结果:
1、医疗影像语义较为简单、结构固定。因此语义信息相比自动驾驶等较为单一,因此并不需要去筛选过滤无用的信息。医疗影像的所有特征都很重要,因此低级特征和高级语义特征都很重要,所以U型结构的skip connection结构(特征拼接)更好派上用场
2、医学影像的数据较少,获取难度大,数据量可能只有几百甚至不到100,因此如果使用大型的网络例如DeepLabv3+等模型,很容易过拟合。大型网络的优点是更强的图像表述能力,而较为简单、数量少的医学影像并没有那么多的内容需要表述,因此也有人发现在小数量级中,分割的SOTA模型与轻量的Unet并没有神恶魔优势
3、医学影像往往是多模态的。比方说ISLES脑梗竞赛中,官方提供了CBF,MTT,CBV等多中模态的数据(这一点听不懂也无妨)。因此医学影像任务中,往往需要自己设计网络去提取不同的模态特征,因此轻量结构简单的Unet可以有更大的操作空间。
三、网络模型搭建与案例探索
1、net搭建
根据上一节我们所讲的unet网络结构,我们可以把net归结为4个功能类模块:卷积、上沉采样、下沉池化以及前向传播,以下逐一分析。
1.1卷积模块
1 | |
在一次卷积中,上层数据通过inchannel输入,outchannel输出。卷积核是3x3,stride、padding值为1的矩阵,而reflect则是对称加强特征提取。在卷积层之后将对数据进行归一化处理,将彩色图像数据的一个通道里的每一个通道维度C按概率赋值为0.
1.2上沉采样

1 | |
以1x1,步长为1的卷积将数据进行降通道传输。
1.3下沉池化

1 | |
将自身数据卷积处理后在进行传输。
1.4前向传播
1 | |
值得注意的是,在上沉采样用前向传播中需要将图片进行重构拼接,在NCHW通道中运行.
1 | |
2、实例测试
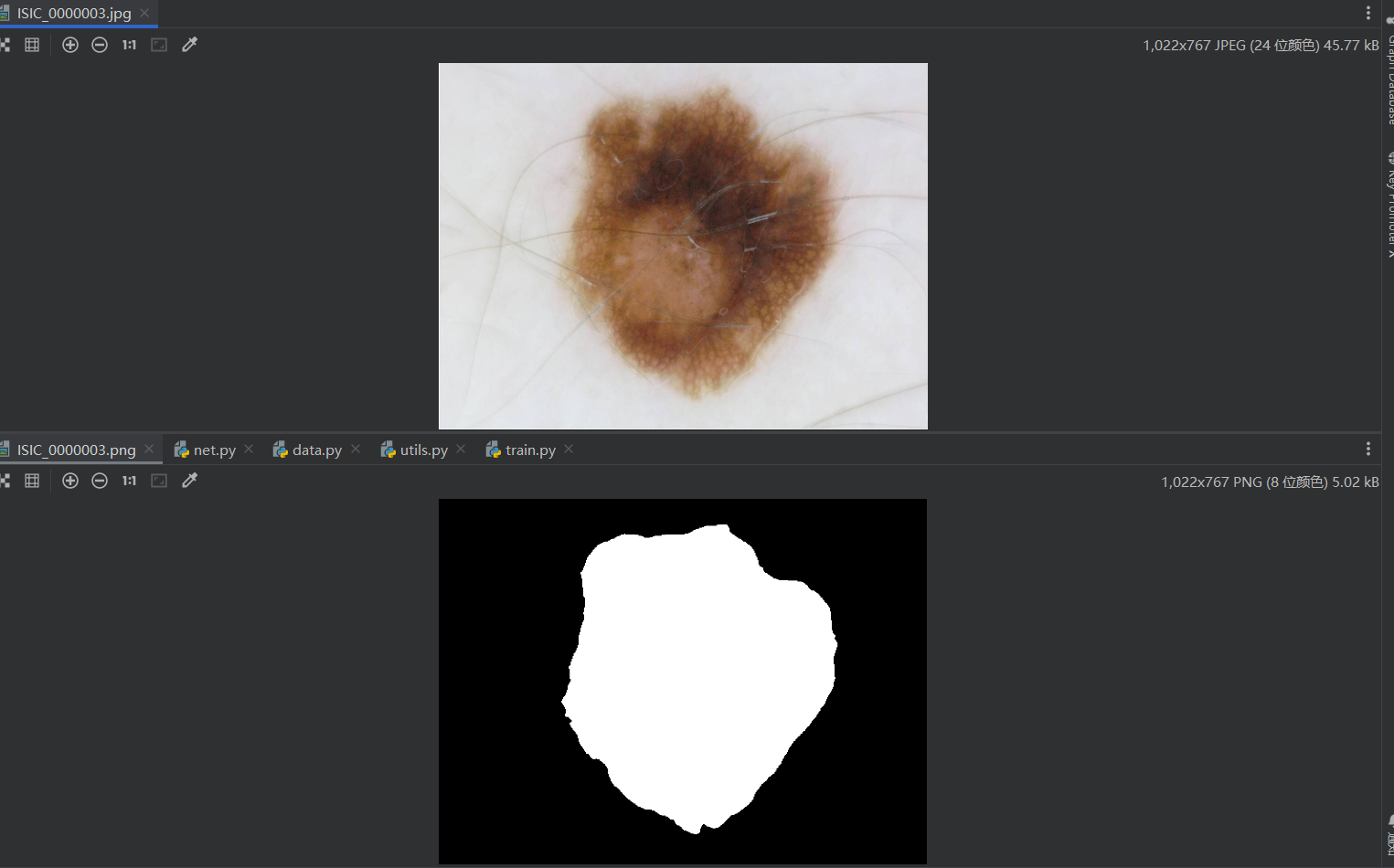
数据集:
原图个例:

标签个例:

整体是对原图进行了暗化来保留高亮部分。
1 | |
在经过7h的训练之后得到model权重参数,我们对其进行test,最终输出结果:

从左到右依次是:原图,暗化图片,预测结果。
说明模型效果良好。
四、医疗影像分割的项目运用
在进行了上述实例测试后,我们对其进行X光医疗图像的分割应用。
首先导入数据集来训练:
训练集:
标签:

在模型训练结束之后,我们可以用一些指标来测试模型性能,语义分割常用的指标是MIOU

1 | |
最后得出测试结果,以下展示其一:
五、总结体会
- 神经网络的搭建是核心步骤,要对应着论文中不能有偏差,尤其是前向传播不能掉以轻心。
- 在数据准备好了之后,数据的预处里很关键,也很困难,特别是对于大量的图片文件,在转化为张量之前要对其进行大量数学处理,来减小训练时特征提取以及模型的计算压力。
- 一块高性能的显卡很重要,我的笔记本是GTX1050的老显卡,在跑7h数据集的时候差点烧了,以后这种还是尽量租服务器跑。
- 测试集也很重要,最后结果要对训练数据进行反向传播,来提高模型准确度,测试集的数据尽量不要与训练集交叉过多。